Controlling user logging in Hadoop
Imagine that you’re a Hadoop administrator, and to make things interesting you’re managing a multi-tenant Hadoop cluster where data scientists, developers and QA are pounding your cluster. One day you notice that your disks are filling-up fast, and after some investigating you realize that the root cause is your MapReduce task attempt logs.
How do you guard against this sort of thing happening? Before we get to that we need to understand where these files exist, and how they’re written. The figure below shows the three log files that are created for each task attempt in MapReduce. Notice that the logs are written to the local disk of the task attempt.
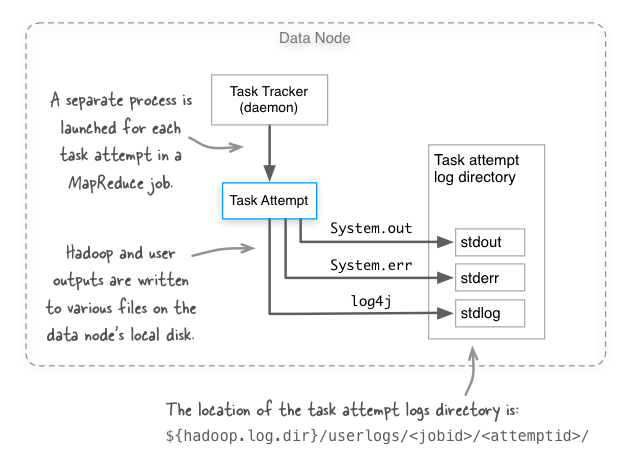
OK, so how does Hadoop normally make sure that our disks don’t fill-up with these task attempt logs? I’ll cover three approaches.
Approach 1: mapred.userlog.retain.hours
Hadoop has a mapred.userlog.retain.hours configurable, which is defined in mapred-default.xml as:
The maximum time, in hours, for which the user-logs are to be retained after the job completion.
Great, but what if your disks are filling up before Hadoop has had a chance to automatically clean them up? It may be tempting to reduce mapred.userlog.retain.hours to a smaller value, but before you do that you should know that there’s a bug with the Hadoop versions 1.x and earlier (see MAPREDUCE-158), where the logs for long-running jobs that run longer than mapred.userlog.retain.hours are accidentally deleted. So maybe we should look elsewhere to solve our overflowing logs problem.
Approach 2: mapred.userlog.limit.kb
Hadoop has another configurable, mapred.userlog.limit.kb, which can be used to limit the file size of stdlog, which is the log4j log output file. Let’s peek again at the documentation:
The maximum size of user-logs of each task in KB. 0 disables the cap.
The default value is 0, which means that log writes go straight to the log file. So all we need to do is to set a non-negative value and we’re set, right? Not so fast - it turns out that this approach has two disadvantages:
- Hadoop and user logs are actually cached in memory, so you’re taking away
mapred.userlog.limit.kbkilobytes worth of memory from your task attempt’s process. - Logs are only written out when the task attempt process has completed, and only contain the last
mapred.userlog.limit.kbworth of log entries, so this can make it challenging to debug long-running tasks.
OK, so what else can we try? We have one more solution, log levels.
Approach 3: Changing log levels
Ideally all your Hadoop users got the memo about minimizing excessive logging. But the reality of the situation is that you have limited control over what users decide to log in their code, but what you do have control over is the task attempt log levels.
If you had a MapReduce job that was aggressively logging in package com.example.mr, then you may be tempted to use the daemonlog CLI to connect to all the TaskTracker daemons and change the logging to ERROR level:
hadoop daemonlog -setlevel <host:port> com.example.mr ERRORYet again we hit a roadblock - this will only change the logging level for the TaskTracker process, and not for the task attempt process. Drat! This really only leaves one option, which is to update your ${HADOOP_HOME}/conf/log4j.properties on all your data nodes by adding the following line to this file:
log4j.logger.com.example.mr=ERRORThe great thing about this change is that you don’t need to restart MapReduce, since any new task attempt processes will pick up your changes to log4j.properties.
About the author


Alex Holmes works on tough big-data problems. He is a software engineer, author, speaker, and blogger specializing in large-scale Hadoop projects. He is the author of Hadoop in Practice, a book published by Manning Publications. He has presented multiple times at JavaOne, and is a JavaOne Rock Star.
If you want to see what Alex is up to you can check out his work on GitHub, or follow him on Twitter or Google+.
RECENT BLOG POSTS
-
Configuring memory for MapReduce running on YARN
This post examines the various memory configuration settings for your MapReduce job.
-
Big data anti-patterns presentation
Details on the presentation I have at JavaOne in 2015 on big data antipatterns.
-
Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
Parquet offers integration with a number of object models, and this post shows how Parquet supports various object models.
-
Using Oozie 4.4.0 with Hadoop 2.2
Patching Oozie's build so that you can create a package targetting Hadoop 2.2.0.
-
Hadoop in Practice, Second Edition
A sneak peek at what's coming in the second edition of my book.