Lexicographically sorting large files in Linux
When I hear the word “sort” my first thought is usually “Hadoop”! Yes, sorting is one thing that Hadoop does well, but if you’re working with large files in Linux the built-in sort command is often all you need.
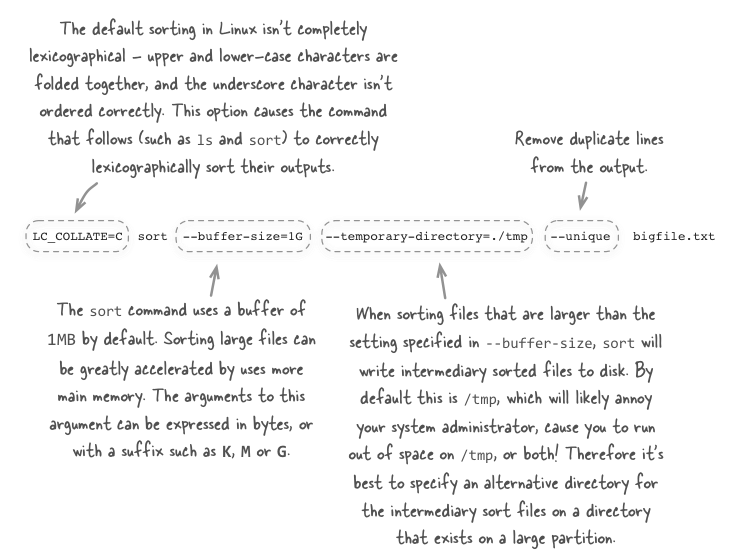
Let’s say you have a large file on a host with 2GB or more of main memory free. The following sort command is a efficient way to lexicographically-order large files.
LC_COLLATE=C sort --buffer-size=1G --temporary-directory=./tmp --unique bigfile.txtLet’s break this command down and examine each part in detail.
About the author


Alex Holmes works on tough big-data problems. He is a software engineer, author, speaker, and blogger specializing in large-scale Hadoop projects. He is the author of Hadoop in Practice, a book published by Manning Publications. He has presented multiple times at JavaOne, and is a JavaOne Rock Star.
If you want to see what Alex is up to you can check out his work on GitHub, or follow him on Twitter or Google+.
RECENT BLOG POSTS
-
Configuring memory for MapReduce running on YARN
This post examines the various memory configuration settings for your MapReduce job.
-
Big data anti-patterns presentation
Details on the presentation I have at JavaOne in 2015 on big data antipatterns.
-
Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
Parquet offers integration with a number of object models, and this post shows how Parquet supports various object models.
-
Using Oozie 4.4.0 with Hadoop 2.2
Patching Oozie's build so that you can create a package targetting Hadoop 2.2.0.
-
Hadoop in Practice, Second Edition
A sneak peek at what's coming in the second edition of my book.