Configuring and tuning MapReduce's shuffle
Once you have outgrown your small Hadoop cluster it’s worth tuning some of the shuffle configurables to ensure that your performance keeps up with the physical growth of your cluster. The figure below shows key configurables in the shuffle stage in Hadoop versions 1.x and earlier, and identifies those that should be tuned.
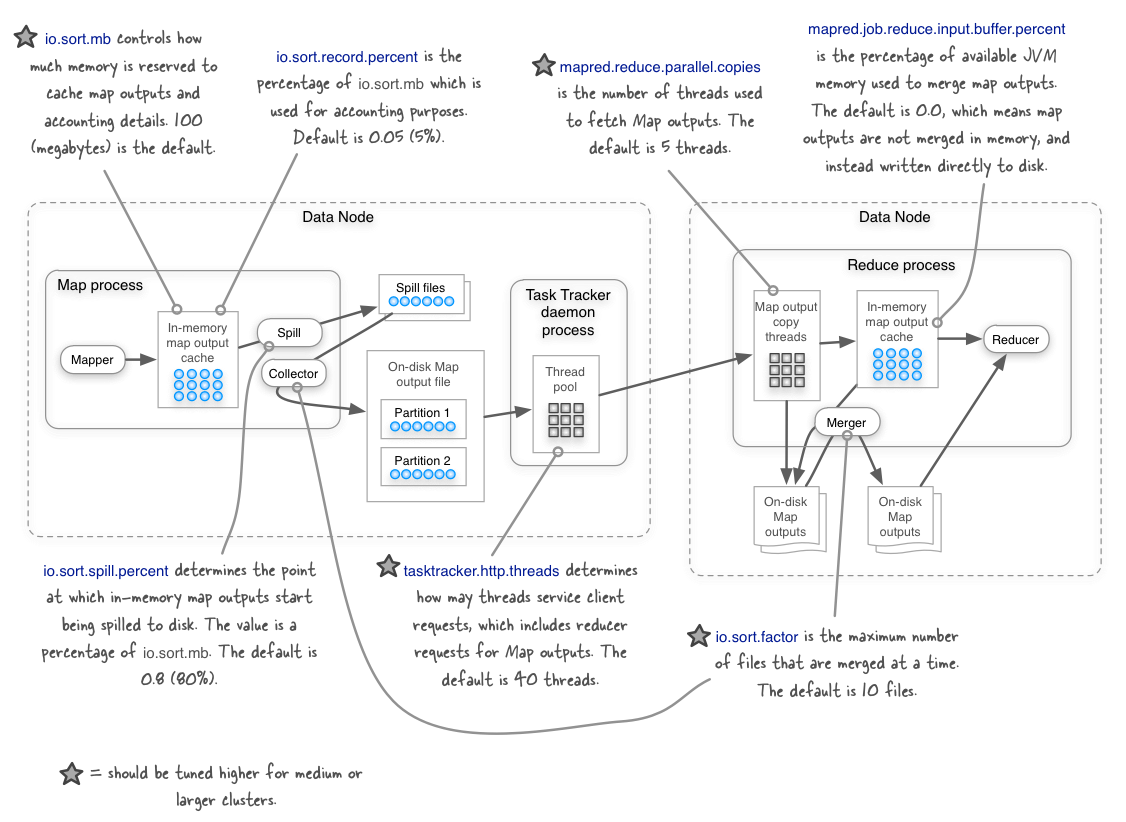
You can read more about these configurables and their default values by looking at mapred-default.xml. My book Hadoop in Practice (Manning Publications) in chapter 6 discusses how some of the configuration values in the figure should be tweaked when you start working with mid to large-size Hadoop clusters.
About the author


Alex Holmes works on tough big-data problems. He is a software engineer, author, speaker, and blogger specializing in large-scale Hadoop projects. He is the author of Hadoop in Practice, a book published by Manning Publications. He has presented multiple times at JavaOne, and is a JavaOne Rock Star.
If you want to see what Alex is up to you can check out his work on GitHub, or follow him on Twitter or Google+.
RECENT BLOG POSTS
-
Configuring memory for MapReduce running on YARN
This post examines the various memory configuration settings for your MapReduce job.
-
Big data anti-patterns presentation
Details on the presentation I have at JavaOne in 2015 on big data antipatterns.
-
Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
Parquet offers integration with a number of object models, and this post shows how Parquet supports various object models.
-
Using Oozie 4.4.0 with Hadoop 2.2
Patching Oozie's build so that you can create a package targetting Hadoop 2.2.0.
-
Hadoop in Practice, Second Edition
A sneak peek at what's coming in the second edition of my book.