Java 6 and 7 with the dotted/dotless I
Imagine you’re working on a project in Java where you are handling text in a language that contains characters outside the standard 128-character ASCII scheme, such as Turkish. How about we focus on the dotted and dotless I:
| Letter | Description | Unicode (decimal) | Unicode (Java hex) |
| İ | Upper-case dotted I | 304 | u0130 |
| I | Upper-case (dotless) Latin I | 73 | u0049 |
| ı | Lower-case dottless I | 305 | u0131 |
| i | Lower-case (dotted) Latin I | 105 | u0069 |
This is how the lower and upper-case versions of the Turkish dotted/dotless “I” relate:
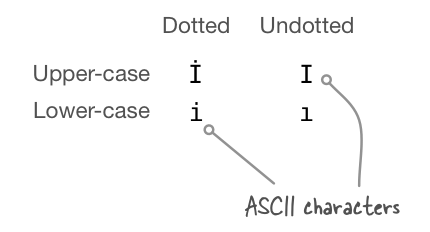
Since we know that the hexadecimal Unicode representation of the upper-case dotted “I” (İ) is u0130, how about we try and and convert it to its lower-case form, which should be the regular lower-case Latin “i”, which in Unicode hexadecimal form is u0069.
System.out.println(String.valueOf('\u0130').toLowerCase());
If we run this same code under Java 6 and Java 7 we get:

Hmm - I may be mistaken, but it looks like under Java 7 the “i” has grown another dot! Let’s see what the Unicode codepoints in the resulting string look like using the following code:
int offset;
for(int i = 0; i < s.length(); i += offset) {
int codepoint = s.codePointAt(i);
offset = Character.charCount(codepoint);
System.out.print(String.format("u%04x ", codepoint));
}
If we run again run this in Java 6 and Java 7 against the toLowerCase method on the upper-case dotted “I” we get:
Java 6: u0069
Java 7: u0069 u0307
It looks like the first codepoint is indeed correct (the Latin lower-case “i”), but what is u0307? Wikipedia tells us) it’s the “combining dot above”, which is to say that it is displayed as a single character (called a grapheme) it modifies the previous character with an additional dot, just like we saw in our example.
What’s puzzling about this is why do we see the behaviour of toLowerCase change between Java versions? If you dig into the Java 7 String class and compare the code against the Java 6 source, you’ll see that the following code was added to Java 7:
} else if (srcChar == '\u0130') { // LATIN CAPITAL LETTER I DOT
lowerChar = Character.ERROR;
}
Basically the end result of this change is that for this specific case (the upper-case dotted I), Java 7 now consults a special Unicode character database (http://www.unicode.org/Public/UNIDATA/SpecialCasing.txt), which provides data on complex case-mappings. Looking at this file you can see several lines for the upper-case dotted I:
CODE LOWER TITLE UPPER LANGUAGE
0130; 0069 0307; 0130; 0130;
0130; 0069; 0130; 0130; tr;
0130; 0069; 0130; 0130; az;Entries with a language take precedence over those without, so in my JVM where the default locale is English, the first row of the mapping is used, which lines-up with the codepoints that we saw outputted in our Java 7 example. Therefore to make Java do the right thing here for Turkish, we need to explicitly specify the Turkish locale (“tr” is the ISO 639 alpha-2 language code for Turkish) to the toLowerCase method:
dumpUnicodeCodePoints(String.valueOf('\u0130').toLowerCase(new Locale("tr")));
This now yields a result consistent with what we expect the Turkish lower-case mapping:
u0069The bottom line is that Java 6 will always convert the upper-case dotted “I” to a lower-case Latin “I”, whereas Java 7 is following the complex Unicode case mapping based on the locale passed into the toLowerCase method, which defaults to Locale.getDefault() if you don’t supply one to the toLowerCase.
Oh, and one last tip - for most lower-case mappings the String.toLowerCase method defers to Character.toLowerCase. But take stock of the advice given in the Character.toLowerCase JavaDoc comment, especially in the second and third paragraphs:
/**
* Converts the character (Unicode code point) argument to
* lowercase using case mapping information from the UnicodeData
* file.
*
* <p> Note that
* {@code Character.isLowerCase(Character.toLowerCase(codePoint))}
* does not always return {@code true} for some ranges of
* characters, particularly those that are symbols or ideographs.
*
* <p>In general, {@link String#toLowerCase()} should be used to map
* characters to lowercase. {@code String} case mapping methods
* have several benefits over {@code Character} case mapping methods.
* {@code String} case mapping methods can perform locale-sensitive
* mappings, context-sensitive mappings, and 1:M character mappings, whereas
* the {@code Character} case mapping methods cannot.
*
* @param codePoint the character (Unicode code point) to be converted.
* @return the lowercase equivalent of the character (Unicode code
* point), if any; otherwise, the character itself.
* @see Character#isLowerCase(int)
* @see String#toLowerCase()
*
* @since 1.5
*/
public static int toLowerCase(int codePoint) {
return CharacterData.of(codePoint).toLowerCase(codePoint);
}
About the author


Alex Holmes works on tough big-data problems. He is a software engineer, author, speaker, and blogger specializing in large-scale Hadoop projects. He is the author of Hadoop in Practice, a book published by Manning Publications. He has presented multiple times at JavaOne, and is a JavaOne Rock Star.
If you want to see what Alex is up to you can check out his work on GitHub, or follow him on Twitter or Google+.
RECENT BLOG POSTS
-
Configuring memory for MapReduce running on YARN
This post examines the various memory configuration settings for your MapReduce job.
-
Big data anti-patterns presentation
Details on the presentation I have at JavaOne in 2015 on big data antipatterns.
-
Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
Parquet offers integration with a number of object models, and this post shows how Parquet supports various object models.
-
Using Oozie 4.4.0 with Hadoop 2.2
Patching Oozie's build so that you can create a package targetting Hadoop 2.2.0.
-
Hadoop in Practice, Second Edition
A sneak peek at what's coming in the second edition of my book.