Bucketing, multiplexing and combining in Hadoop - part 1
This is the first blog post in a series which looks at some data organization patterns in MapReduce. We’ll look at how to bucket output across multiple files in a single task, how to multiplex data across multiple files, and also how to coalesce data. These are all common patterns that are useful to have in your MapReduce toolkit.
We’ll kick things off with a look at bucketing data outputs in your map or reduce tasks. By default when using a FileOutputFormat-derived OutputFormat (such as TextOutputFormat), all the outputs for a reduce task (or a map task in a map-only job) are written to a single file in HDFS.
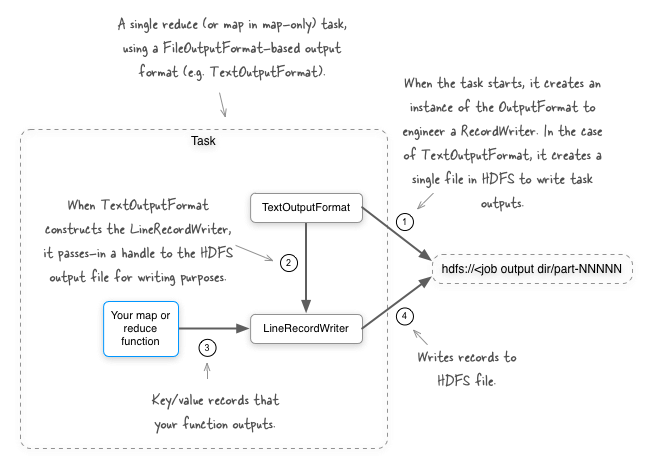
Imagine a situation where you have user activity logs being streamed into HDFS, and you want to write a MapReduce job to better organize the incoming data. As an example a large organization with multiple products may want to bucket the logs based on the product. To do this you’ll need the ability to write to multiple output files in a single task. Let’s take a look at how we can make that happen.
MultipleOutputFormat
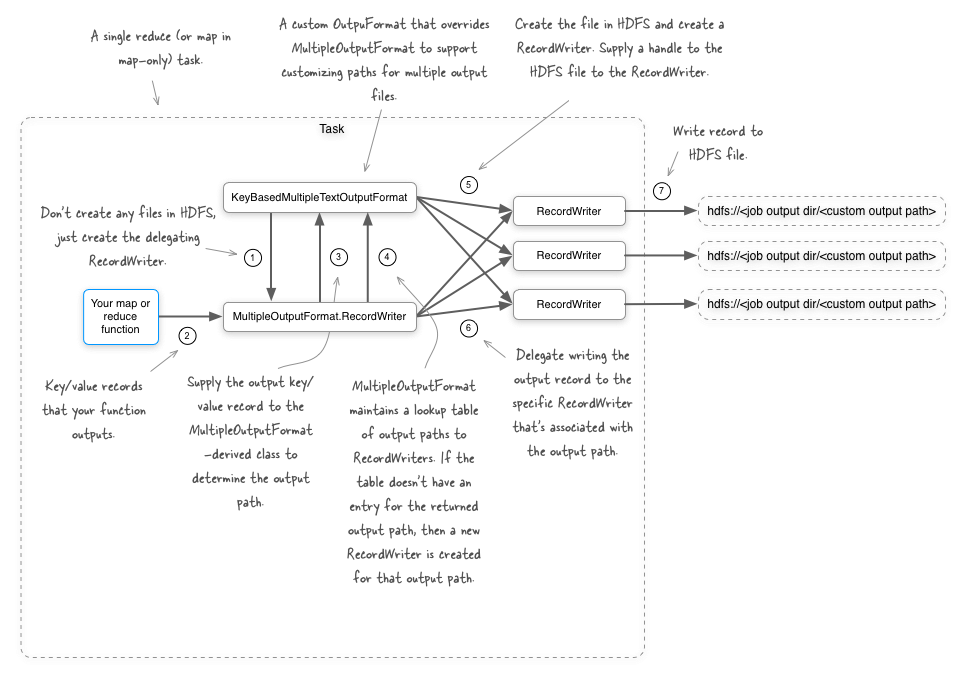
There are a few ways you can achieve your goal, and the first option we’ll look at is the MultipleOutputFormat class in Hadoop. This is an abstract class that lets you do the following:
- Define the output path for each and every key/value output record being emitted by a task.
- Incorporate the input paths into the output directory for map-only jobs.
- Redefine the key and value that are used to write to the underlying
RecordWriter. This is useful in situations where you want to remove data from the outputs as it duplicates data in the filename. - For each output path, define the
RecordWriterthat should be used to write the outputs.
OK enough with the words - let’s look at some data and code. First up is the simple data we’ll use in our example - imagine you work at a fruit market with locations in multiple cities, and you have a purchase transaction stream which contains the store location along with the fruit that was purchased.
cupertino apple
sunnyvale banana
cupertino pear
To help bucket your data for future analysis, you want to bin each record into city-specific files. For the simple data set above you don’t want to filter, project or transform your data, just bucket it out, so a simple identity map-only job will do the job. To force more than one mapper, we’ll write the data to two separate files.
$ TAB="$(printf '\t')"
$ hdfs -put - file1.txt << EOF
cupertino${TAB}apple
sunnyvale${TAB}banana
EOF
$ hdfs -put - file2.txt << EOF
cupertino${TAB}pear
EOF
Here’s the code which will let you write city-specific output files.
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.IdentityMapper;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Arrays;
/**
* An example of how to use {@link org.apache.hadoop.mapred.lib.MultipleOutputFormat}.
*/
public class MOFExample extends Configured implements Tool {
/**
* Create output files based on the output record's key name.
*/
static class KeyBasedMultipleTextOutputFormat
extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
}
/**
* The main job driver.
*/
public int run(final String[] args) throws Exception {
String csvInputs = StringUtils.join(Arrays.copyOfRange(args, 0, args.length - 1), ",");
Path outputDir = new Path(args[args.length - 1]);
JobConf jobConf = new JobConf(super.getConf());
jobConf.setJarByClass(MOFExample.class);
jobConf.setNumReduceTasks(0);
jobConf.setMapperClass(IdentityMapper.class);
jobConf.setInputFormat(KeyValueTextInputFormat.class);
jobConf.setOutputFormat(KeyBasedMultipleTextOutputFormat.class);
FileInputFormat.setInputPaths(jobConf, csvInputs);
FileOutputFormat.setOutputPath(jobConf, outputDir);
return JobClient.runJob(jobConf).isSuccessful() ? 0 : 1;
}
/**
* Main entry point for the utility.
*
* @param args arguments
* @throws Exception when something goes wrong
*/
public static void main(final String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MOFExample(), args);
System.exit(res);
}
}
Run this code and you’ll see the following files in HDFS, where /output is the job output directory:
$ hadoop fs -lsr /output
/output/cupertino/part-00000
/output/cupertino/part-00001
/output/sunnyvale/part-00000
If you look at the output files you’ll see that the files contain the correct buckets.
$ hadoop fs -lsr /output/cupertino/*
cupertino apple
cupertino pear
$ hadoop fs -lsr /output/sunnyvale/*
sunnyvale banana
Awesome, you have your data bucketed by store. Now that we have everything working, let’s look at what we did to get there. We had to do two things to get this working:
Extend MultipleTextOutputFormat
This is where the magic happened - let’s look at that class again.
static class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
}
You are working with text, which is why you extended MultipleTextOutputFormat, a class that in turn extends MultipleOutputFormat. MultipleTextOutputFormat is a simple class which instructs the MultipleOutputFormat to use TextOutputFormat as the underlying output format for writing out the records. If you were to use MultipleOutputFormat as-is it behaves as if you were using the regular TextOutputFormat, which is to say that it’ll only write to a single output file. To write data to multiple files you had to extend it, as with the example above.
The generateFileNameForKeyValue method allows you to return the output path for an input record. The third argument, name, is the original FileOutputFormat-created filename, which is in the form “part-NNNNN”, where “NNNNN” is the task index, to ensure uniqueness. To avoid file collisions, it’s a good idea to make sure your generated output paths are unique, and leveraging the original output file is certainly a good way of doing this. In our example we’re using the key as the directory name, and then writing to the original FileOutputFormat filename within that directory.
Specify the OutputFormat
The next step was easy - specify that this output format should be used for your job:
jobConf.setOutputFormat(KeyBasedMultipleTextOutputFormat.class);
Earlier we also mentioned that you can use the input path as part of the output path, which we will look at next.
Using the input filename as part of the output filename in map-only jobs
What if we wanted to keep the input filename as part of the output filename? This only works for map-only jobs, and can be accomplished by overriding the getInputFileBasedOutputFileName method. Let’s look at the following code to understand how this method fits into the overall sequence of actions that the MultipleOutputFormat class performs:
public void write(K key, V value) throws IOException {
// get the file name based on the key
String keyBasedPath = generateFileNameForKeyValue(key, value, myName);
// get the file name based on the input file name
String finalPath = getInputFileBasedOutputFileName(myJob, keyBasedPath);
// get the actual key
K actualKey = generateActualKey(key, value);
V actualValue = generateActualValue(key, value);
RecordWriter<K, V> rw = this.recordWriters.get(finalPath);
if (rw == null) {
// if we don't have the record writer yet for the final path, create
// one
// and add it to the cache
rw = getBaseRecordWriter(myFS, myJob, finalPath, myProgressable);
this.recordWriters.put(finalPath, rw);
}
rw.write(actualKey, actualValue);
};
The getInputFileBasedOutputFileName method is called with the output of generateFileNameForKeyValue, which contains our already-customized output file. Our new KeyBasedMultipleTextOutputFormat can now be updated to override getInputFileBasedOutputFileName and append the original input filename to the output filename:
static class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat {
@Override
protected String generateFileNameForKeyValue(Object key, Object value, String name) {
return key.toString() + "/" + name;
}
@Override
protected String getInputFileBasedOutputFileName(JobConf job, String name) {
String infilename = new Path(job.get("map.input.file")).getName();
return name + "-" + infilename;
}
If you run with your modified OutputFormat class you’ll see the following files in HDFS, confirming that the input filenames are now concatenated to the end of each output file.
$ hadoop fs -lsr /output
/output/cupertino/part-00000-file1.txt
/output/cupertino/part-00001-file2.txt
/output/sunnyvale/part-00000-file1.txt
The implementation of getInputFileBasedOutputFileName in MultipleOutputFormat doesn’t do anything interesting by default, but if you set the value of the mapred.outputformat.numOfTrailingLegs configurable to an integer greater than 0, then the getInputFileBasedOutputFileName will use part of the input path as the output path.
Let’s see what happens when we set the value to 1:
jobConf.setInt("mapred.outputformat.numOfTrailingLegs", 1);
The output files in HDFS now exactly mirror the input files used for the job:
$ hadoop fs -lsr /output
/output/file1.txt
/output/file2.txt
If we set mapred.outputformat.numOfTrailingLegs to 2, and our input files exist in the /inputs directory, then our output directory looks like this:
$ hadoop fs -lsr /output
/output/input/file1.txt
/output/input/file2.txt
Basically as you keep incrementing mapred.outputformat.numOfTrailingLegs, then MultipleOutputFormat will continue to go up the parent directories of the input file and use them in the output path.
Modifying the output key and value
It’s very possible that the actual key and value you want to emit are different from those that were used to determine the output file. In our example, we took the output key and wrote to a directory using the key name. If you do that keeping the key in the output file may be redundant. How would we modify the output record so that the key isn’t written? MultipleOutputFormat has your back with the generateActualKey method.
class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
@Override
protected Text generateActualKey(Text key, Text value) {
return null;
}
}
The returned value from this method replaces the key that’s supplied to the underlying RecordWriter, so if you return null as in the above example, no key will be written to the file.
$ hadoop fs -lsr /output/cupertino/*
apple
pear
$ hadoop fs -lsr /output/sunnyvale/*
banana
You can achieve the same result for the output value by overriding the generateActualValue method.
Changing the RecordWriter
In our final step we’ll look at how you can leverage multiple RecordWriter classes for different output files. This is accomplished by overriding the getRecordWriter method. In the example below we’re leveraging the same TextOutputFormat for all the files, but it gives you a sense of what can be accomplished.
static class KeyBasedMultipleTextOutputFormat extends MultipleTextOutputFormat<Text, Text> {
@Override
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString() + "/" + name;
}
@Override
public RecordWriter<Text, Text> getRecordWriter(FileSystem fs, JobConf job, String name, Progressable prog) throws IOException {
if (name.startsWith("apple")) {
return new TextOutputFormat<Text, Text>().getRecordWriter(fs, job, name, prog);
} else if (name.startsWith("banana")) {
return new TextOutputFormat<Text, Text>().getRecordWriter(fs, job, name, prog);
}
return super.getRecordWriter(fs, job, name, prog);
}
}
Conclusion
When using MultipleOutputFormat, give some thought to the number of distinct files that each reducer will create. It would be prudent to plan your bucketing so that you have a relatively small number of files.
In this post we extended MultipleTextOutputFormat, which is a simple extension of MultipleOutputFormat that supports text outputs. MultipleSequenceFileOutputFormat also exists to support SequenceFiles in a similar fashion.
So what are the shortcomings with the MultipleOutputFormat class?
- If you have a job that uses both map and reduce phases, then
MultipleOutputFormatcan’t be used in the map-side to write outputs. Of course,MultipleOutputFormatworks fine in map-only jobs. - All
RecordWriterclasses must support exactly the same output record types. For example, you wouldn’t be able to support a RecordWriter that emitted<IntWritable, Text>for one output file, and have another RecordWriter that emitted<Text, Text>. MultipleOutputFormatexists in themapredpackage, so it won’t work with a job that requires use of themapreducepackage.
All is not lost if you bump into either one of these issues, as you’ll discover in the next blog post in this series.
About the author


Alex Holmes works on tough big-data problems. He is a software engineer, author, speaker, and blogger specializing in large-scale Hadoop projects. He is the author of Hadoop in Practice, a book published by Manning Publications. He has presented multiple times at JavaOne, and is a JavaOne Rock Star.
If you want to see what Alex is up to you can check out his work on GitHub, or follow him on Twitter or Google+.
RECENT BLOG POSTS
-
Configuring memory for MapReduce running on YARN
This post examines the various memory configuration settings for your MapReduce job.
-
Big data anti-patterns presentation
Details on the presentation I have at JavaOne in 2015 on big data antipatterns.
-
Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
Parquet offers integration with a number of object models, and this post shows how Parquet supports various object models.
-
Using Oozie 4.4.0 with Hadoop 2.2
Patching Oozie's build so that you can create a package targetting Hadoop 2.2.0.
-
Hadoop in Practice, Second Edition
A sneak peek at what's coming in the second edition of my book.