Avro's built-in sorting
Avro has a little-known gem of a feature which allows you to control which fields in an Avro record are used for partitioning, sorting and grouping in MapReduce. The following figure gives a quick refresher as to what these terms mean. Oh, and don’t take the placement of the “sorting” literally - sorting actually occurs on both the map and reduce side - but it’s always performed in the context of a specific partition (i.e. for a specific reducer).
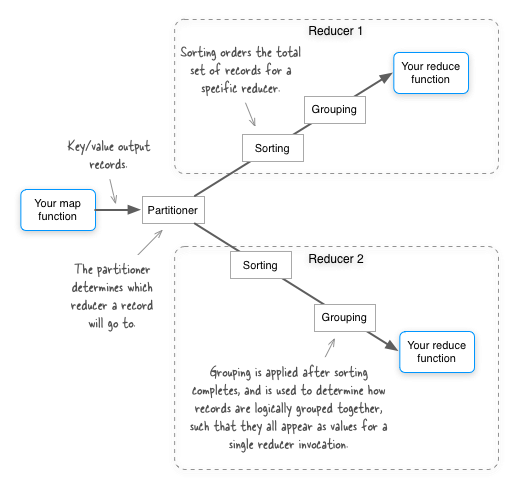
By default all the fields in an Avro map output key are used for partitioning, sorting and grouping in MapReduce. Let’s walk through an example and see how this works. You’ll begin with a simple schema GitHub source:
{"type": "record", "name": "com.alexholmes.avro.WeatherNoIgnore",
"doc": "A weather reading.",
"fields": [
{"name": "station", "type": "string"},
{"name": "time", "type": "long"},
{"name": "temp", "type": "int"},
{"name": "counter", "type": "int", "default": 0}
]
}
We’re going to see what happens when we run this code against a small sample data set, which we’ll generate using Avro code GitHub source:
File input = tmpFolder.newFile("input.txt");
AvroFiles.createFile(input, WeatherNoIgnore.SCHEMA$, Arrays.asList(
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(1).setTemp(3).build(),
WeatherNoIgnore.newBuilder().setStation("IAD").setTime(1).setTemp(1).build(),
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(2).setTemp(1).build(),
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(1).setTemp(2).build(),
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(1).setTemp(1).build()
).toArray());
To understand how Avro is partitioning, sorting and grouping the data, we’ll write an identity mapper and reducer, with a small enhancement to the reducer to increment the counter field for each record we see in an individual reducer instance GitHub source:
package com.alexholmes.avro.sort.basic;
import com.alexholmes.avro.WeatherNoIgnore;
import org.apache.avro.mapred.AvroKey;
import org.apache.avro.mapred.AvroValue;
import org.apache.avro.mapreduce.AvroJob;
import org.apache.avro.mapreduce.AvroKeyInputFormat;
import org.apache.avro.mapreduce.AvroKeyOutputFormat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class AvroSort {
private static class SortMapper
extends Mapper<AvroKey<WeatherNoIgnore>, NullWritable,
AvroKey<WeatherNoIgnore>, AvroValue<WeatherNoIgnore>> {
@Override
protected void map(AvroKey<WeatherNoIgnore> key, NullWritable value, Context context)
throws IOException, InterruptedException {
context.write(key, new AvroValue<WeatherNoIgnore>(key.datum()));
}
}
private static class SortReducer
extends Reducer<AvroKey<WeatherNoIgnore>, AvroValue<WeatherNoIgnore>,
AvroKey<WeatherNoIgnore>, NullWritable> {
@Override
protected void reduce(AvroKey<WeatherNoIgnore> key,
Iterable<AvroValue<WeatherNoIgnore>> values, Context context)
throws IOException, InterruptedException {
int counter = 1;
for (AvroValue<WeatherNoIgnore> WeatherNoIgnore : values) {
WeatherNoIgnore.datum().setCounter(counter++);
context.write(new AvroKey<WeatherNoIgnore>(WeatherNoIgnore.datum()),
NullWritable.get());
}
}
}
public boolean runMapReduce(final Job job, Path inputPath, Path outputPath)
throws Exception {
FileInputFormat.setInputPaths(job, inputPath);
job.setInputFormatClass(AvroKeyInputFormat.class);
AvroJob.setInputKeySchema(job, WeatherNoIgnore.SCHEMA$);
job.setMapperClass(SortMapper.class);
AvroJob.setMapOutputKeySchema(job, WeatherNoIgnore.SCHEMA$);
AvroJob.setMapOutputValueSchema(job, WeatherNoIgnore.SCHEMA$);
job.setReducerClass(SortReducer.class);
AvroJob.setOutputKeySchema(job, WeatherNoIgnore.SCHEMA$);
job.setOutputFormatClass(AvroKeyOutputFormat.class);
FileOutputFormat.setOutputPath(job, outputPath);
return job.waitForCompletion(true);
}
}
If you look at the output of the job below, you’ll see that the output is sorted across all the fields, and that the sorting is in field ordinal order. What this means is that when MapReduce is sorting these records, it compares the station field first, then the time field second, and so on according to the ordering of the fields in the Avro schema. This is pretty much what you’d expect if you write your own complex Writable type, and your comparator compared all the fields in order.
{"station": "IAD", "time": 1, "temp": 1, "counter": 1}
{"station": "SFO", "time": 1, "temp": 1, "counter": 1}
{"station": "SFO", "time": 1, "temp": 2, "counter": 1}
{"station": "SFO", "time": 1, "temp": 3, "counter": 1}
{"station": "SFO", "time": 2, "temp": 1, "counter": 1}
Oh, and before we move on notice that the value for the counter field is always 1, meaning that each reducer was only fed a single key/vaue pair, which makes sense since our identity mapper only emitted a single value for each key, the keys are unique, and the MapReduce partitioner, sorter and grouper were using all the fields in the record.
Excluding fields for sorting
Avro gives us the ability to indicate that specific fields should be ignored when performing ordering functions. In MapReduce these fields are ignored for sorting/partitioning and grouping in MapReduce, which basically means that we have the ability to perform secondary sorting. Let’s examine the following schema GitHub source:
{"type": "record", "name": "com.alexholmes.avro.Weather",
"doc": "A weather reading.",
"fields": [
{"name": "station", "type": "string"},
{"name": "time", "type": "long"},
{"name": "temp", "type": "int", "order": "ignore"},
{"name": "counter", "type": "int", "order": "ignore", "default": 0}
]
}
It’s pretty much identical to the first schema, the only difference being that the last two fields have an additional “order” field whose value is set to “ignore”. Let’s run the same (other than modified to work with the different schema) MapReduce code GitHub source as above against this new schema and examine the outputs.
{"station": "IAD", "time": 1, "temp": 1, "counter": 1}
{"station": "SFO", "time": 1, "temp": 3, "counter": 1}
{"station": "SFO", "time": 1, "temp": 2, "counter": 2}
{"station": "SFO", "time": 1, "temp": 1, "counter": 3}
{"station": "SFO", "time": 2, "temp": 1, "counter": 1}
There are a couple of notable differences between this output, and the output from the previous schema which didn’t have any ignored fields. First, it’s clear that the temp field isn’t being used in the sorting, which makes sense since we specified that it should be ignored in the schema. However, more interestingly, note the value of the counter field. All records that had identical station and time values went to the same reducer invocation, evidenced by the increasing value of counter. This is essentially secondary sort!
Sort order
The Avro documentation will give you an idea around how ordering is performed for different Avro types. Field ordering is ascending by default, but you can make it descending by setting the value of the “order” field to “descending”:
{"type": "record", "name": "com.alexholmes.avro.Weather",
"doc": "A weather reading.",
"fields": [
{"name": "station", "type": "string"},
{"name": "time", "type": "long"},
{"name": "temp", "type": "int", "order": "descending"},
{"name": "counter", "type": "int", "order": "ignore", "default": 0}
]
}
Limitations
Now, all of this greatness isn’t without some limitations:
- You can’t support two MapReduce jobs that use the same Avro key, but have different sorting/partitioning/grouping requirements. Although it’s conceivable that you could create a new instance of the Avro schema and set the ignored flags for these fields yourself.
- The partitioner, sorter and grouping functions in MapReduce all work off of the same fields (i.e. they all ignore fields that set as ignored in the schema). This means that your options for secondary sorting are limited. For example, you wouldn’t be able to partition all stations to the same reducer, and then group by station and time.
- Ordering uses a field’s ordinal position to determine its order within the overall set of fields to be ordered. In other words, in a two-field record, the first field is always compared before the second. There’s no way to change this behavior other than flipping the order of the fields in the record.
Having said all of that - the “ignoring fields” feature for sorting is pretty awesome, and something that will no doubt come in handy in my future MapReduce work.
About the author


Alex Holmes works on tough big-data problems. He is a software engineer, author, speaker, and blogger specializing in large-scale Hadoop projects. He is the author of Hadoop in Practice, a book published by Manning Publications. He has presented multiple times at JavaOne, and is a JavaOne Rock Star.
If you want to see what Alex is up to you can check out his work on GitHub, or follow him on Twitter or Google+.
RECENT BLOG POSTS
-
Configuring memory for MapReduce running on YARN
This post examines the various memory configuration settings for your MapReduce job.
-
Big data anti-patterns presentation
Details on the presentation I have at JavaOne in 2015 on big data antipatterns.
-
Understanding how Parquet integrates with Avro, Thrift and Protocol Buffers
Parquet offers integration with a number of object models, and this post shows how Parquet supports various object models.
-
Using Oozie 4.4.0 with Hadoop 2.2
Patching Oozie's build so that you can create a package targetting Hadoop 2.2.0.
-
Hadoop in Practice, Second Edition
A sneak peek at what's coming in the second edition of my book.